Claude AI faces API 529 overload errors disrupting code and chat tasks

Claude AI’s API 529 overload error has halted critical coding tasks and left users of Claude Code frustrated by service downtime. When an outage hits a popular AI assistant, it’s more than just a red dashboard—developers lose momentum, projects stall, and contingency plans get tested. With over 4,000 outage reports logged in minutes, the recent API 529 overload made one thing clear: AI coding tools are capable, but not immune to demand shocks. Here’s what happened, what it means for developers, and practical tactics for staying productive when the backend melts down.
What is the Claude AI API 529 overload error?
The Claude AI API 529 overload error is a server-reported status code that indicates Claude’s cloud backend has been overwhelmed. For developers interfacing with APIs, a 529 error specifically flags a provider-side problem: the infrastructure can’t handle the current load, so requests are temporarily rejected.
In practical terms, that means when you submit a prompt—whether for code completion, chat, or project scaffolding—the Claude Code service hits a bottleneck. The provider’s systems choose to shed incoming requests rather than letting performance degrade for everyone.
API status 529 isn’t a standardized HTTP code, but cloud platforms use it internally to mark user-facing requests as “overloaded, try again later” events. Unlike a client-side error (e.g., 4xx), a 529 tells you the problem lives on the AI service’s servers, not in your local environment or payload.
For anyone relying on Claude’s coding tools, the implication is direct: when these overloads strike, there’s nothing fundamentally wrong with your input or machine—it’s the remote AI assistant itself that’s down for the count.
When did Claude AI outages begin and how widespread are they?
According to DownDetector data and user reports, Claude AI’s most recent wave of outages began around 8:30 pm EST on Sunday. Within 15 minutes, more than 4,000 independent outage incidents were registered, pinpointing a sudden collapse in service availability. The problem quickly ballooned to affect multiple modes of access, from Claude Code (their flagship coding assistant) to chat functionality.
Quotes from affected users posted to DownDetector highlight the pervasiveness and variety of impacts:
- “Start 5 minutes ago: Claude Code Opus 4.8 has an API error - status 529 Overloaded.”
- “Took longer than usual. Tried again later (attempt 4), great, it's been doing this for a while.”
- “Trying to work on the desktop app. Works great. I'm running multiple projects: one in the desktop app and two in different browsers. The browser project is closed, but the desktop app is working for me so far.”
The incident wasn’t region- or interface-specific: desktop and browser clients both saw disruptions, though some users reported partial functionality depending on the client and project state. The outage affected both the interactive Claude chat service and direct coding workflows in Claude Code.
Within the developer community, frustration mounted as the downtime persisted, and the flood of reports on DownDetector underscores just how tightly integrated Claude AI has become in real-world coding pipelines.
11 production screens. Auth, DB, Stripe — all wired.
The SaaS Dashboard Kit ships everything already connected. No Vercel config, no Supabase account. Live demo at saas.otf-kit.dev.
How does the API 529 error affect Claude AI and coding tasks?
The API 529 overload error has an immediate, practical effect on every developer depending on Claude for code generation or editing. Once the overload state is triggered, prompts sent to Claude Code or chat are met with failure responses—either delayed completions, outright request rejections, or in some cases, silent timeouts.
Users reported needing to retry their requests multiple times, as shown by quotes like:
- “Took longer than usual. Tried again later (attempt 4), great, it’s been doing this for a while.”
This pattern—rapid-fire retries, alternating between working and failing sessions—turns smooth AI-assisted workflows into start-stop marathons. Multi-project users felt it especially hard: while one desktop app task might survive, browser-based coding in parallel tabs was often disabled.
The result is workflow lockup:
- Project scaffolding and refactor tasks pause mid-stream.
- Coding assistant conversations drop context or fail to return outputs.
- Automated code review or test suite triggers miss their windows.
It’s not just about a stalled prompt. Downtime on an AI coding assistant like Claude forces developers into context-switching, manual workarounds, or full fallback to alternatives, introducing real friction and breakage in tightly-coupled development environments.
One user summarized the exasperation: “I should have used OpenAI to pre-plan this prompt. Claude fails every few days.” This isn’t just a temporary inconvenience—it’s a bigger reliability question that teams have to build around.
What are typical causes of API 529 overload errors in AI services?
API 529 overload errors usually signal a surge in request volume, resource exhaustion, or unhandled backend failure in cloud AI services:
- Traffic spikes: Unexpected loads—such as surges when new features launch or peak usage hours—can outstrip provisioned capacity, maxing out server processors or GPU allocators.
- Resource contention: Heavy batches of concurrent requests compete for limited compute, leading the load balancer or API gateway to start dropping excess requests with an overload status.
- Backend failures: If a component (data store, model server, orchestration layer) goes down, incoming API calls may queue up until capacity exhausts, then receive a 529 as the system recovers or reroutes traffic.
Most AI cloud APIs, including those underlying coding assistants, rely on auto-scaling infrastructure. But when demand outpaces these safeguards—whether due to legitimate growth or an infrastructure bug—errors like 529 are a last-ditch protection against outright crashes or data loss.
Best practices for dev teams usually involve rate limiting, exponential backoff, and pooling across providers to absorb these service ripples. But when a provider’s own backend is the bottleneck, even the smartest client-side tricks won’t fully shield users from downtime.
How can developers work around Claude AI API 529 errors today?
While a 529 overload is out of client control, several engineering tactics can reduce disruption:
-
Automate retry logic. Instead of manual resubmission, use exponential backoff to retry failed prompts after increasing intervals:
// Pseudocode for solid API call with retry on 529 async function callClaudeWithRetry(prompt) { for (let i = 0; i < 5; i++) { const res = await fetchClaudeAPI(prompt) if (res.status !== 529) return res.data await sleep(2 ** i * 1000) // Exponential backoff } throw new Error('Claude overload: try again later') } -
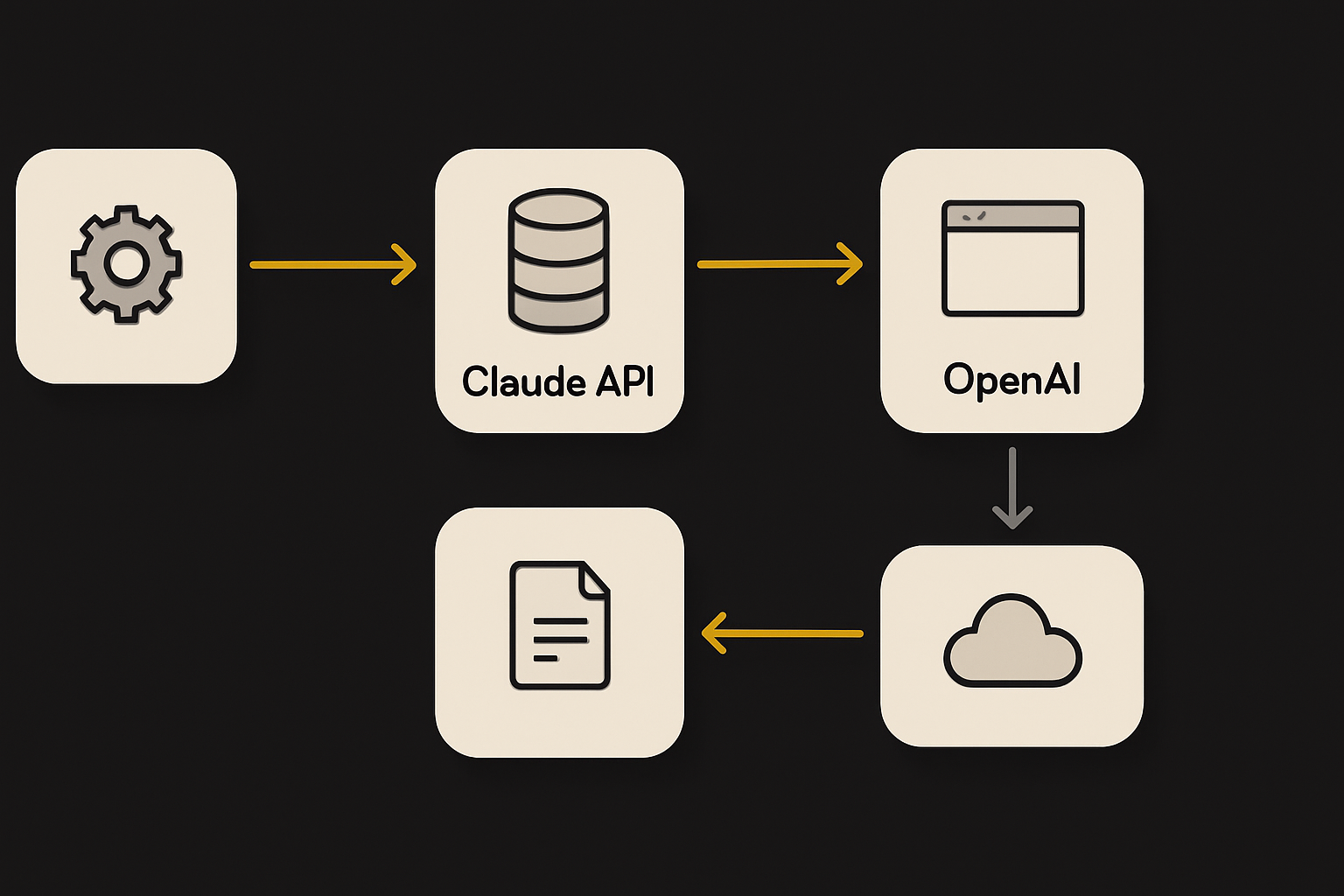
Load distribution. When possible, split non-critical tasks across timeframes, or balance workloads between Claude and backup AI APIs. If you have both Claude and OpenAI access configured, route secondary prompts away during an outage:
function pickProvider(primaryStatus) { return primaryStatus === 529 ? 'openai' : 'claude' } -
Monitor status and outages. Subscribe to trackers like DownDetector for real-time signals on service health. If you’re on-call for automation or critical deployments, set up alerting on API failure rates crossing a threshold:
# Watch for 529s in logs and alert tail -f claudecode.log | grep "529" | while read; do notify-oncall "Spike in Claude API 529 overloads" done -
Join community channels. Forums or developer Slacks often surface workarounds, restoration ETAs, or provider context sooner than official dashboards.
-
Plan for fallback. Build your development pipelines so you can degrade gracefully: have scripts, prompts, or code ready to migrate to another assistant if Claude goes dark for extended periods. Factor in state sync between sessions if using browser and desktop apps concurrently.
No mitigation is perfect—some manual intervention is inevitable when an AI provider is fully saturated. But teams with tested fallback flows and observable status will recover faster and burn less time than those learning on the fly.
If you’re new to solid error handling, see OTF’s AI assistant reliability and troubleshooting guides or AI API error handling best practices for battle-tested patterns.
Has the Claude AI provider responded to the outage?
As of publication, Crowder (the Claude AI provider) has not issued any public statement or update acknowledging or explaining the API 529 overload outage. This radio silence added to user frustration, with many in community forums calling for more proactive status updates and postmortem transparency.
The absence of a root cause explanation—combined with repeated, unscheduled service failures—can erode developer trust in a tool’s stability. In downtime windows like these, even minimal communication (“we’re investigating”, “ETA”) is far less frustrating than silence.
For teams betting on external AI APIs, a provider’s response time and transparency are as important as their models’ sophistication. No update from Crowder means developers have to rely on peer-to-peer tracking tools and workarounds for situational awareness.
Provider communication and trust stay durable—regardless of the model—when there’s a channel for absorbing uncertainty and downtimes aren’t swept under the rug.
Keeping workflows moving when Claude API 529 errors hit
The Claude AI API 529 overload error exposed how quickly a coding assistant can become a single-point-of-failure for modern development teams. Over 4,000 outage reports in minutes, cross-platform lockout, and non-existent provider communication forced users to improvise recovery strategies mid-project.
When your primary AI coding assistant stalls with a 529 error, the difference between a full stop and a minor blip is preparation: automated retries, multi-provider fallbacks, and live monitoring all keep friction low. OTF's own orchestration patterns treat AI tool churn as a constant—wrapping providers, not picking favorites, and assuming every API may go read-only at any time.
When the backend fails, your process doesn't have to. Embrace resilience strategies now, and when the next overload hits, you’ll spend less time firefighting and more time shipping.
Ship the product, not the setup.
- 11 production screens — auth, billing, team, analytics, settings
- Real Postgres + Stripe + Better Auth, all wired on day 1
- CLAUDE.md pre-tuned so your agent extends instead of regenerates