Cisco AI unveils FAPO for smarter pipeline-aware prompt optimization

Getting LLM pipelines right still comes down to how you optimize your prompts. Cisco AI’s FAPO (Fully Automated Prompt Optimization) shows up with exactly the kind of innovation that practitioners have been begging for: a pipeline-aware, open source system that delivers measurable accuracy gains and pulls the operator out of the loop. In Cisco’s own benchmarks, FAPO outperforms state-of-the-art tools like GEPA on 15 out of 18 tasks — and when it escalates to full pipeline restructuring, the accuracy improvement can hit +33.8pp. This is not a theoretical advancement. The entire stack is orchestrated by Claude Code agents, supports Codex as an optimizer, and is licensed under Apache 2.0 for open adoption. For anyone wrestling with diagnosing pipeline failures or seeking reproducible LLM accuracy improvements, Cisco AI’s FAPO is a real leap forward in prompt optimization.
What is Cisco AI FAPO?
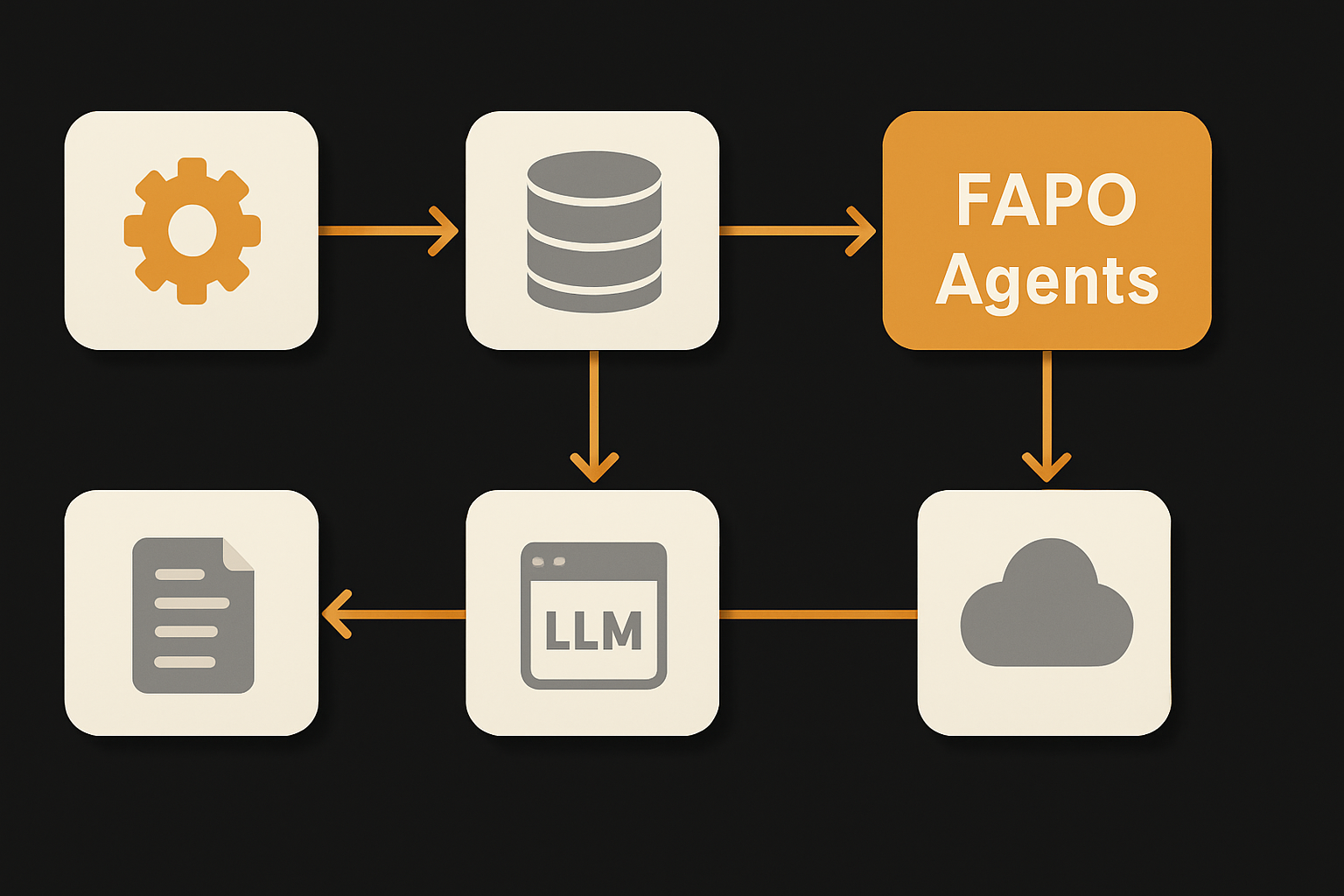
Cisco AI FAPO is a fully automated, open-source framework for prompt optimization across multi-step LLM pipelines. The name stands for Fully Automated Prompt Optimization, but the value goes deeper than automation: FAPO’s core innovation is treating the entire LLM chain as a first-class target, not just isolated prompts.
A FAPO project is structured around self-contained "tenant" directories. Each tenant manages one optimization task — its prompts, datasets, chain definitions, scoring logic, and config — and runs independently so unrelated LLM pipeline projects can execute in parallel without collision. The framework’s core engine, hephaestus, is domain-agnostic and handles all evaluation, chain execution, and scoring logic.
Orchestration is powered by Claude Code agents, with drop-in support for Codex. Define a dataset, an initial pipeline, and your prompt set, then FAPO takes over: it evaluates your pipeline, identifies where failures emerge, proposes and validates prompt and pipeline variants, and cycles until it either hits the target accuracy or exhausts configured options. Everything is open source under Apache 2.0, removing licensing friction for experimentation and production scaling.
How does pipeline-aware prompt optimization work in FAPO?
FAPO’s pipeline-aware approach means it doesn’t just treat the pipeline as an opaque black box. Instead, it performs step-wise failure attribution, isolating where in the multi-stage LLM pipeline answers go off the rails. That attribution drives the heart of FAPO’s automated loop.
The basic cycle looks like this:
- Dataset and initial prompt ingest — You drop in structured datasets and baseline prompts for the task. The chain definition specifies the step order and expected outputs.
- Automated evaluation — The engine processes the pipeline over the dataset, logging step-wise outputs and the aggregate answers.
- Failure classification and attribution — When answers miss the mark, FAPO analyzes intermediate results to attribute failures to specific steps, rather than the pipeline as a monolith.
- Variant proposal and validation — Based on which step failed, FAPO escalates through three layers of change:
- Prompt-level tweaks: Rewriting or reframing the prompt tied to the failing step.
- Parameter changes: Adjusting temperature, sampling, or other model-level parameters.
- Chain restructuring: Modifying the pipeline structure itself (shuffling or splitting steps, adding pre/post-processing logic).
- Iterate and evaluate — Each variant runs through validation on dataset splits, looping until accuracy targets are met or all options are exhausted.
All orchestration, proposal, and review steps are handled by Claude Code (or Codex) agents, enabling a repeatable, hands-free optimization cycle, while still enforcing reproducibility guardrails like train-split-only result checking and explicit human-in-the-loop review on every change proposal.
11 production screens. Auth, DB, Stripe — all wired.
The SaaS Dashboard Kit ships everything already connected. No Vercel config, no Supabase account. Live demo at saas.otf-kit.dev.
Why is step-level failure attribution critical for LLM pipelines?
Step-level failure attribution is the big enable for practical LLM pipeline tuning. Most prompt optimizers only track final outputs. That means when accuracy drops, you’re stuck fishing through dozens of intermediate steps — by hand — to guess where it broke.
FAPO automates this attribution, so when your final result misses, it can pinpoint exactly which step's output was wrong. Consider a question-answering chain: maybe everything works until the retrieval step fails to extract relevant context. Manual inspection means reading dozens of intermediate files for every test case — a labor bottleneck. FAPO's logic narrows this instantly.
That step-scoped targeting enables much more surgical adjustments. Instead of globally tweaking the starting prompt or doing random parameter sweeps, the optimizer knows to propose a prompt rewrite only for the retrieval step, or to bump temperature just on the summarization step. Debugging and accuracy improvement become orders of magnitude more efficient, enabling a path to higher baseline performance without endless trial and error.
How to use FAPO today: a step-by-step guide
Anyone can try FAPO — it’s open source, optimized for drop-in experimentation, and the workflow matches pipelines most LLM shops already use. Here’s how to get it running:
-
Set up your environment
Clone the repo from Cisco AI’s public release (link from MarkTechPost article).
Install dependencies and export your Claude or Codex API credentials.git clone <fapo-repo-url> cd fapo pip install -r requirements.txt export CLAUDE_API_KEY=sk-xxx # or export CODEX_API_KEY=sk-yyy -
Prepare your dataset and initial pipeline
Place a task-specific dataset (inputs + gold standard outputs) and initial prompt files in a new tenant directory:tenants/ my-task/ prompts/ dataset.jsonl chain.yaml scorer.py config.yaml -
Run the optimization loop
Launch optimization with:python fapo.py --tenant my-task --agent claudeFAPO will process your pipeline on the dataset, attribute failures per step, and start proposing prompt, parameter, or chain structure edits. Every variant is validated before adoption.
-
Inspect and iterate
FAPO drops evaluation reports, intermediate outputs, and proposed variants into your tenant directory. You review or accept changes, optionally run with Codex agents, or fine-tune configuration for stricter or more exploratory optimization. -
Integrate improvements
Once FAPO converges on a performant chain, lock in the new prompt set and pipeline config. Integration is a direct copy-back — the output files are your new deployable.
The entire optimization process is designed to be reproducible and safe for production experimentation, with clear variant provenance and guardrails against overfitting or accidental regression.
How does FAPO compare to other prompt optimizers?
In Cisco AI’s evaluation, FAPO consistently outperforms state-of-the-art prompt optimizers like GEPA. Out of 18 competitive model-benchmark tasks, FAPO beat GEPA on 15, with a mean gain of +14.1pp in typical prompt optimization comparisons. Where FAPO escalates to actual pipeline restructuring (as on HoVer and IFBench), it not just wins — it dominates, registering a mean gain of +33.8pp across all six head-to-head pairs. On the AIME benchmark, GEPA notched one win, but the margin is described as within sampling noise — hardly a practical disadvantage.
Here’s what changes:
| Optimizer | Focus | Escalates Beyond Prompts | Step-Level Attribution | Open Source? | Wins (18 tasks) | Mean Gain (pipeline) |
|---|---|---|---|---|---|---|
| FAPO | Pipeline, prompt, params | Yes | Yes | Yes (A2.0) | 15 | +33.8pp |
| GEPA | Prompt | No | No | Unstated | 3 | N/A |
FAPO’s openness (Apache 2.0 license) removes friction both for collaborative research and for real-world deployment, while the technical advances enable gains unreachable by prompt-only tuning.
What are future directions and implications for LLM applications?
FAPO’s structure is built for scaling to real-world, production LLM stacks. The approach enables several high-value outcomes for LLM application builders:
- Scalability: The multi-tenant pattern adapts naturally to dozens or hundreds of pipelines, each isolated and self-configuring.
- Automated, granular tuning: Step-level failure attribution and escalation means fewer regressions, faster convergence, and higher accuracy with less trial and error.
- Open research and extension: Apache 2.0 licensing and generic chain/tenant structure lets external contributors build new scoring mechanisms, integrate alternative orchestrators, or scale out to as-yet-unsupported agent systems.
- Ecosystem maturation: By shipping reproducibility scaffold (training-split-only inspection, explicit review), FAPO helps raise the bar for trustworthy AI pipeline tuning tools.
For the LLM field, FAPO’s approach points to a future where tuning complex AI chains — now a bottleneck and labor sink — is as automated, scalable, and reproducible as today's ML training pipelines.
FAPO is prompt optimization the way LLM practitioners want it
Prompt and pipeline tuning isn’t a solved problem, but FAPO’s pipeline-aware, step-level approach is a real advance — and not just on paper. The empirical gains are proven, the guardrails are designed for production, and the open licensing means you can adopt or extend FAPO in your own stack today. For teams aiming at reliable LLM performance, reproducible optimization, and freedom from endless prompt guesswork, FAPO is now the reference implementation.
Explore the open source repo, run it on your chain, and experience what pipeline-aware, step-wise prompt optimization can enable for your LLM applications.
Ship the product, not the setup.
- 11 production screens — auth, billing, team, analytics, settings
- Real Postgres + Stripe + Better Auth, all wired on day 1
- CLAUDE.md pre-tuned so your agent extends instead of regenerates