Explore Neo4j Agent Memory Service for persistent, structured LLM agent memory

Ephemeral memory is the default for most AI agents today. Reasoning chains, past facts, and tool calls vanish after the prompt, forcing repeated, redundant processing and limiting the practical applications of LLM-powered software. The Neo4j Agent Memory Service (NAMS) offers a serious counterpoint: a managed cloud service that gives agents persistent, structured memory rooted in Neo4j Aura’s graph database and vector indexing. For LLM devs wrestling with stunted context or chaotic memory hacks, this is the kind of foundational bridge persistent agents actually need. NAMS is experimental and early, but it’s available today for hands-on use via Neo4j Labs. Building agents that genuinely remember — at scale, across sessions, safely and structurally — just became possible.
What is the Neo4j Agent Memory Service (NAMS)?
NAMS is a managed cloud memory backend for AI agents. Built by Neo4j Labs and surfaced via REST API or MCP client, it gives LLM agents access to persistent, structured memory they can query, augment, and compress across sessions and users. The backbone is a fully managed Neo4j Aura graph DB with native vector indexes — so you’re not just storing text, but building an evolving knowledge graph where short-term conversation, long-term entities, and past tool calls are all interconnected.
NAMS covers the primitives an agent needs:
- Storage: All agent interactions, facts, and reasoning steps go into the graph.
- Entity Extraction: NAMS parses agent inputs to extract key entities and relationships.
- Deduplication: Redundant or repeated facts are merged automatically.
- Embedding: Texts are embedded and indexed for efficient vector search, not just simple text match.
- Compression: Old and excess context is background-compressed into persistent summaries.
- Retrieval: A single API call returns not just what’s most recent, but what’s contextually relevant — across conversation, extracted knowledge, and the agent’s process history.
Everything goes through the NAMS API or MCP, so you never see raw database internals. For the full breakdown, Neo4j’s Medium article details their Labs experimental release.
Why do LLM agents need persistent memory?
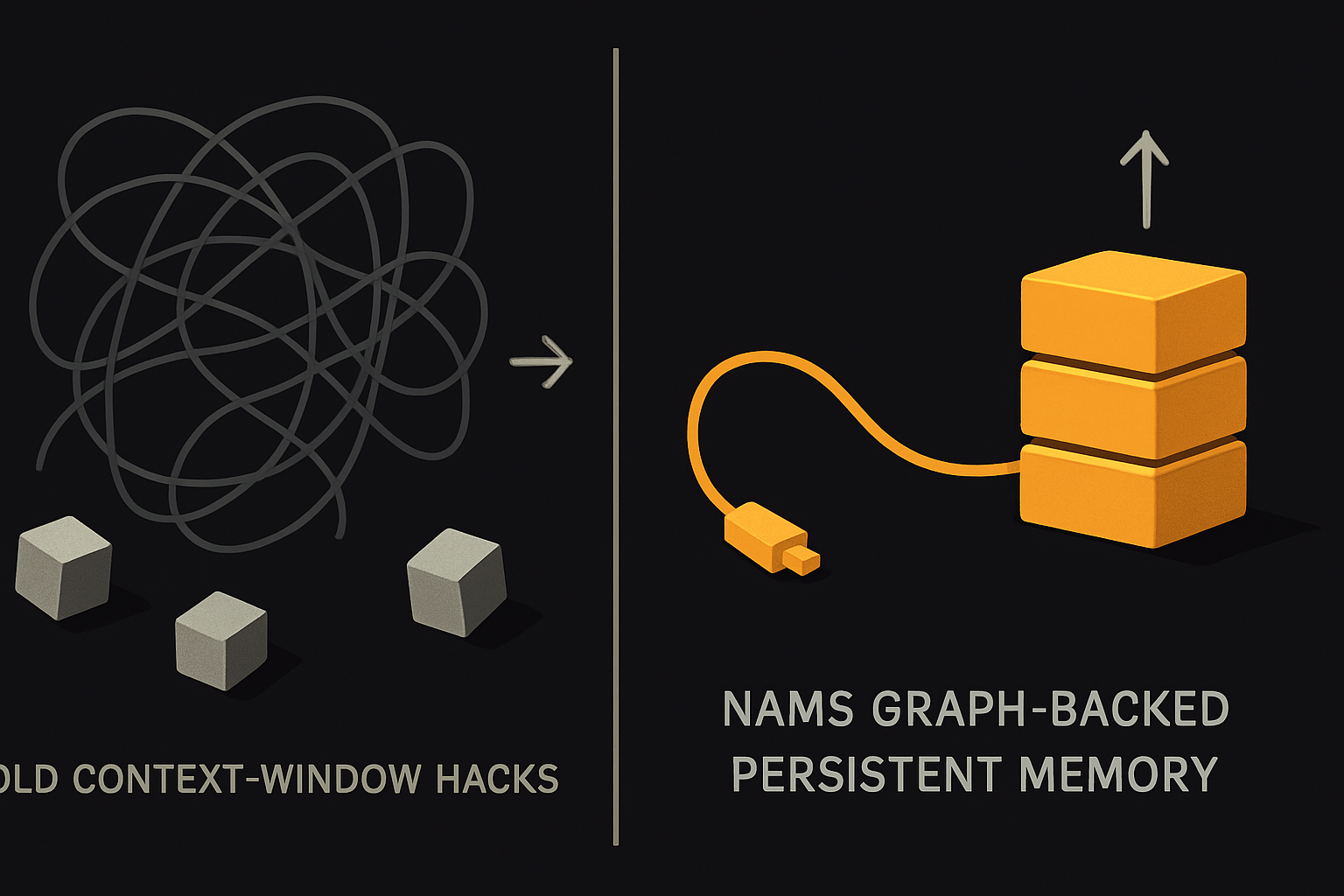
Context windows only get you so far. The default trick — stuffing conversation transcripts or salient text into an LLM’s fixed context — breaks as soon as context grows long, facts contradict, or continuity gets fuzzy. Standard memory hacks:
- Append N-turn transcripts (“Here’s what you just saw…”)
- Use cosine similarity to “retrieve” relevant snippets
- Stitch results together with prompt glue
All of these are band-aids around a fundamental limitation: when memory is ephemeral, the agent can’t maintain a persistent worldview. Every user must repeat context endlessly. Contradictory statements aren’t resolved, just overstuffed into a fixed window.
Examples:
- A code-assistant LLM keeps forgetting refactored functions after each session.
- A chat agent repeats onboarding steps because user traits aren’t retained.
- “Relevant” facts retrieved by embedding vectors are just text, divorced from logical structure — they don’t help the agent reason over relationships.
NAMS addresses this by building every memory — short-term, long-term, and step-wise — into a graph-backed persistent model. Instead of wrangling loose text, you have structured entities and relationships, deduplicated, vector-indexed, and queriable over time and sessions.
11 production screens. Login, database, payments — all wired.
The SaaS Dashboard Kit ships everything already connected. Nothing to set up. Live demo at saas.otf-kit.dev.
How does NAMS work architecturally?
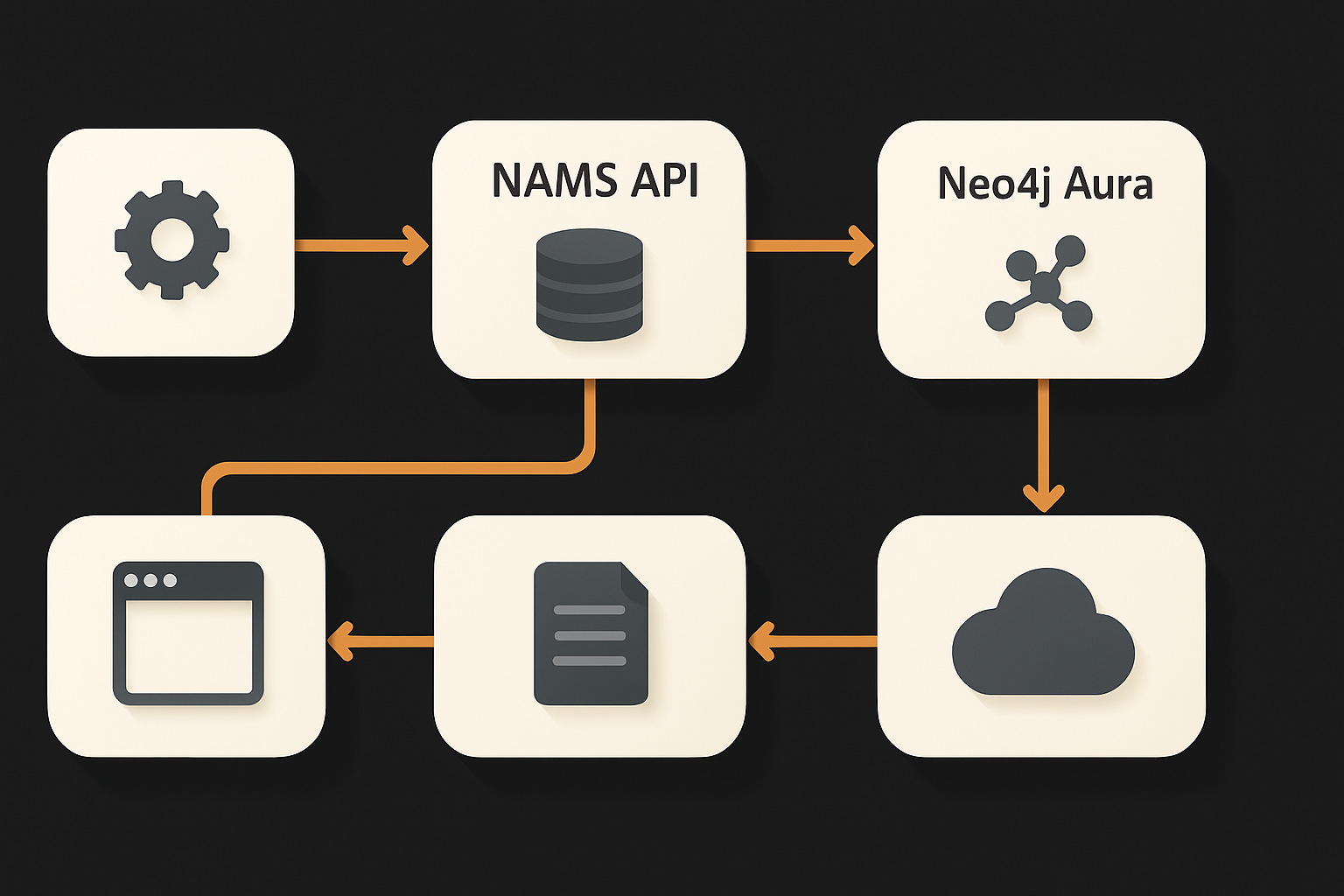
NAMS sits between your agent and memory as a managed microservice. The request flow is simple:
- Agent → HTTP REST or MCP client: Every memory query, addition, or update begins with a POST to the cloud NAMS endpoint.
- NAMS → Neo4j Aura: The backend is a provisioned Aura graph database. It’s the substrate for storing all nodes (e.g., messages, entities, tool calls) and edges (relationships, steps).
- Pipeline orchestration: For every new memory or query, NAMS runs entity extraction, deduplication, embedding (using model of choice for vectors), and background compression. The result: each workspace has its own graph, organized by entities and time, with relevant vectors for fast lookup.
- Retrieval: Fetching context returns a set of connected nodes—conversational turns, entities, past reasoning steps—all filtered and ranked contextually, not just by time or similarity.
A typical context flow might look like this:
# Send a message to be remembered
curl -X POST "https://nams.neo4j.com/api/v1/memory" \
-H "Authorization: Bearer $NAMS_TOKEN" \
-d '{"workspace": "my-agent", "text": "Customer Alex Smith upgraded to premium on June 3rd."}'# Retrieve memory for context
curl -X GET "https://nams.neo4j.com/api/v1/memory?workspace=my-agent&query=\"Alex Smith\"" \
-H "Authorization: Bearer $NAMS_TOKEN"
# Returns JSON: connected facts, entity nodes, and related tool calls.Compression and deduplication run as background jobs — no agent logic needed. The console exposes each workspace’s graph via tabs (Dashboard, Entities, etc.), letting you view memory as it’s processed and connected.
Experimental status: NAMS is Neo4j Labs–labeled (community supported, not yet a fully managed product). Features, pipelines, and endpoints may evolve rapidly, and you’re beta-testing live.
How to use Neo4j Agent Memory Service today?
You don’t need to wait for a GA launch — NAMS is open now for agents in active development. Here’s how to start:
-
Sign up with Neo4j Labs: Visit labs.neo4j.com and request NAMS early access. Accept the experimental caveats and terms.
-
Access the NAMS console: Once your workspace is live, you can log in to the NAMS dashboard. The opening Dashboard tab summarizes service health and processing status for your workspace’s memory operations.
-
Configure your agent: You get either an API key (for raw HTTP) or connect an MCP-compatible agent. For REST, this pattern works in any language:
export NAMS_TOKEN=... curl -X POST "https://nams.neo4j.com/api/v1/memory" \ -H "Authorization: Bearer $NAMS_TOKEN" \ -d '{"workspace": "support-bot", "text": "User reported bug in ticket #9134."}'For MCP workflows, config mirrors your agent platform’s plugin system:
{ "memory": { "provider": "nams", "token": "<your-nams-token>", "workspace": "support-bot" } } -
Navigation in the console: The NAMS console surfaces your memory as tabs:
- Dashboard: System status
- Entities: Extracted structured facts/nodes
- Conversations: Short-term memory (message chains)
- Reasoning: Tool calls, steps, LLM chains
- Raw: Underlying unprocessed chunks
Each tab is a different slice of your workspace graph — no guesswork needed.
-
Community support and caveats: NAMS is experimental; support is handled on a best-effort community basis. Expect new features and breaking changes as Labs iterates.
In short: NAMS can be integrated today, and most agents will need only minor HTTP or plugin glue code.
Benefits and limitations of NAMS
Benefits:
- Persistent, structured memory: Agents get recall beyond ephemeral context—facts, entities, and relationships persist across runs.
- Scalable managed service: No self-hosting, no scaling headaches. Neo4j Aura under the hood.
- Native vector indexing: Efficient semantic search, not just string-matching, with retrieval grounded in graph structures.
- Reduces context overload: No more juggling max-token limits or endless transcript stuffing; relevant context is surgically retrieved as needed.
- Improved reasoning continuity: Steps, tool calls, and factual threads are encoded as nodes, not forgotten by the next session.
Current limitations:
- Experimental (Labs) status: Features and APIs are volatile; no production SLAs. Community support, not managed support.
- Early access: You’ll hit missing features or API changes. If you need a stable contract, this isn’t it yet.
- Ecosystem evolving: Downstream tools (agent runtimes, langchains) may not natively support NAMS without glue code.
For projects tolerating churn in favor of a real breakthrough in agent memory, the trade is clear.
What does the future hold for NAMS and AI agent memory?
Expect NAMS to evolve rapidly — Neo4j Labs positions it as a testbed for the next generation of agent memory primitives. Anticipate:
- Feature expansion: New compression and retrieval techniques, deeper entity modeling, more efficient embeddings.
- Integration: Smoother support for LLM frameworks out of the box.
- Wider adoption: As memory services become foundational for long-context agents, expect competition but also consolidation around graph-backed, vector-indexed approaches.
- User impact: Developers experimenting with NAMS now will shape how persistent agent memory becomes standard, not a patch.
Structured, managed agent memory isn’t a “nice to have” for advanced AI—it’s the next foundation. NAMS is risky and raw, but it’s also early access to that future.
The durable layer for agent memory is finally here
Neo4j Agent Memory Service (NAMS) enables persistent, structured, and scalable memory for LLM agents — finally breaking the cycle of ephemeral, lossy recall and unstructured context hacks. By rooting memory in a graph DB with native vector indexing, Neo4j delivers a durable path for agents to remember, reason, and grow over time. Builders can sign up with Neo4j Labs and wire NAMS into their agents today, experimenting at the frontier. If you care about building AI that actually remembers (and isn’t just an expensive parrot), this is a milestone you should be testing now.

Ship the product, not the setup.
- 11 production screens — auth, billing, team, analytics, settings
- Real database, payments, and login — all wired on day 1
- AI configs pre-tuned so your agent extends instead of regenerates